行業新聞與部落格
生成式人工智慧的 6 種危險以及解決這些危險的措施
生成式人工智慧的結果可以在您線上消費的媒體以及您工作所依賴的資訊中看到。但生成式人工智慧並非沒有風險和挑戰……
人工智慧(AI)是人類最偉大的成就之一;它可以用於從解決利基和全球問題到透過自動化簡化業務運營的各種用途。有一類人工智慧可以根據現有內容的模式建立各種極其逼真的媒體——從技術文件和翻譯到超現實的影象、影片和音訊內容。這稱為生成式人工智慧,因為它使用現有的內容資料集來識別模式並使用它們來生成新內容。(稍後我們將詳細討論人工智慧和生成式人工智慧之間的區別。)
一些流行的生成人工智慧工具的示例包括:
- ChatGPT — 一種聊天機器人,使用大量資料集生成類似人類的響應並提供資訊。
- Google Pixel 8 的 Magic Editor — 一種影象編輯工具,使使用者能夠使用生成式 AI 編輯影象。
- Dall-E 2 — 一種影象和藝術生成器工具,使使用者能夠刪除和操作元素。
- DeepBrain — 影片製作和頭像生成工具。
但儘管生成式人工智慧有諸多“光明”和好處,但也有必須討論的陰暗面。雖然生成式人工智慧確實可以用來創造令人難以置信的事物,但它也可以用來造成傷害——無論是有意還是無意。
作為一個社會,無論是作為個人還是作為專業人士,我們面臨著哪些生成人工智慧風險和挑戰?公共和私營部門正在採取哪些措施來解決這些問題?
讓我們來討論一下。
我們正在討論什麼……
- 生成式人工智慧的結果可以在您線上消費的媒體以及您工作所依賴的資訊中看到。但生成式人工智慧並非沒有風險和挑戰……
- 6 生成式人工智慧的風險和挑戰
- 1. 利用虛假媒體制造虛假敘述、欺騙消費者、傳播虛假資訊
- 2. 生成不準確或捏造的資訊
- 3. 侵犯個人隱私權和期望
- 受保護的資訊可能會無意中被共享
- 生成式人工智慧工具可能會導致個人資料無意洩露
- 4. 使用 Deepfakes 來羞辱和攻擊個人
- 5. 開發新的網路攻擊渠道和方法
- 網路犯罪分子可以製作更可信的網路釣魚訊息
- 社會工程師和其他壞人可以更有效地進行“骯髒行為”
- 壞人可以使用生成人工智慧來嘗試識別變通辦法並獲取秘密
- 6. 生成式人工智慧引發新的智慧財產權和版權侵權問題
- 生成式人工智慧與傳統人工智慧之間的差異概述
- 正在採取哪些措施來解決基於生成人工智慧的風險和擔憂
- 歐盟成員國正在討論人工智慧法案
- 美國領導人呼籲制定有關安全和安全使用人工智慧的標準和指南
- 全球組織正在共同制定人工智慧媒體標準
- 美國立法者旨在為未來針對違法者採取法律行動鋪平道路
- 關於生成式人工智慧風險和危險的最終想法
6 生成式人工智慧的風險和挑戰
如果您看過弗朗西斯教皇穿著蓬鬆的白色 Balenciaga 夾克的照片,或者看過馬克·扎克伯格談論“誰控制了‘達達’[資料],誰就控制了未來”的影片,那麼您就看到了深度偽造內容。Deepfake 影象和影片只是生成人工智慧內容的幾個例子。

Deepfake 技術可以用來創造有趣、娛樂性的內容;然而,它也可用於建立旨在欺騙、欺騙和操縱他人的內容。它可以用來讓員工進行欺詐性銀行轉賬或控制公眾輿論。
瞭解了這一點,現在是時候探討我們在現代技術不斷改進過程中面臨的一些最大的生成式人工智慧風險和擔憂了。
1. 利用虛假媒體制造虛假敘述、欺騙消費者、傳播虛假資訊
我們眼睛看到的、耳朵聽到的都是真實性的有力證明。但是,如果我們無法相信我們所看到或聽到的東西怎麼辦?想象一下,有人制作了一段從未發生過的悲慘事件的虛假影片,以激發某些行動。例如,從未發生過的恐怖襲擊,或者關於政治候選人做了非法或被認為在道德或倫理上應受譴責的事情的虛假資訊,以引起反應。
有人可能會使用虛假錄音來操縱對政客或其他公眾人士的看法。他們可能會發佈政治候選人處於妥協立場或場景的虛假照片,以損害他們的聲譽。即使後來發現影片、影象或音訊是假的,也為時已晚;損害已經造成。
即使是使用生成人工智慧來誤導消費者的廣告也是禁忌。(有人可能會說所有廣告都是煩人且具有誤導性的,但這是另一天的辯論……)正是出於這樣的原因,美國兩黨立法者提出了兩項立法,旨在禁止在與選舉相關的媒體中秘密使用人工智慧,以及廣告。
- 保護選舉免受人工智慧欺騙法案 (S.2770)。我們將在本文後面詳細討論這一問題,但“劇透警報”是,這項立法旨在禁止傳播與聯邦政治候選人有關的人工智慧生成的欺騙性媒體。
- 真正的政治廣告法 (HR 3044)。該法案旨在為在廣告中負責任地使用生成式人工智慧內容創造更大的透明度和問責制。
2. 生成不準確或捏造的資訊
與所有新技術一樣,前進的道路上也會遇到困難和坎坷。生成式人工智慧技術面臨的問題之一是它們的準確性有限。如果他們的分析和創作基於不準確或欺詐性的資訊,那麼他們的輸出也將是不準確的。
以流行的生成式人工智慧工具 ChatGPT 為例,它歷來沒有連線到網際網路,並且“對 2021 年之後的世界和事件的瞭解有限”。然而,當 OpenAI 今年早些時候釋出外掛時,這種情況發生了部分變化,使得人工智慧驅動的聊天機器人能夠在某些用例中訪問第三方應用程式。ChatGPT 的使用條款甚至警告說,所提供的資訊可能不準確,組織和個人需要進行盡職調查:
“人工智慧和機器學習是快速發展的研究領域。我們不斷努力改進我們的服務,使其更加準確、可靠、安全和有益。鑑於機器學習的機率性質,在某些情況下使用我們的服務可能會導致不正確的輸出,無法準確反映真實的人物、地點或事實。您應該根據您的用例評估任何輸出的準確性,包括對輸出進行人工審查。”
OpenAI 在其常見問題解答中提到的一些例子包括捏造事實、引用和引文(該公司稱之為“幻覺”)和歪曲資訊。
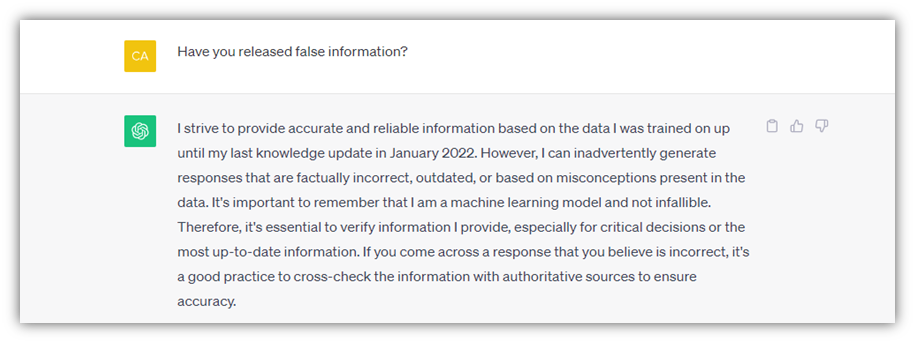
Google Bard 是承認自身缺點的人工智慧的另一個例子:
斯坦福大學和加州大學伯克利分校的研究人員指出,同一生成人工智慧服務的兩個模型之間存在明顯差異。在這種情況下,他們研究了 GPT-3.5 和 GPT-4,並發現模型執行七個類別的不同任務的能力存在顯著波動(即漂移)。
根據研究:
“我們發現 GPT-3.5 和 GPT-4 的效能和行為會隨著時間的推移而發生很大變化。例如,GPT-4(2023 年 3 月)在識別質數與合數方面是合理的(準確率 84%),但 GPT-4(2023 年 6 月)在這些相同問題上表現不佳(準確率 51%)。部分原因是 GPT-4 遵循思維鏈提示的便利性下降。有趣的是,GPT-3.5 在這個任務中 6 月份比 3 月份要好得多。與 3 月份相比,6 月份 GPT-4 不太願意回答敏感問題和民意調查問題。6 月,GPT-4 在多跳問題上的表現優於 3 月,而 GPT-3.5 在此任務上的表現有所下降。GPT-4 和 GPT-3.5 在 6 月份程式碼生成中的格式錯誤都比 3 月份更多。我們提供的證據表明,GPT-4 遵循使用者指令的能力隨著時間的推移而下降,這是許多行為漂移背後的常見因素之一。總體而言,我們的研究結果表明,“相同”法學碩士服務的行為可以在相對較短的時間內發生巨大變化,這凸顯了對法學碩士進行持續監控的必要性。”
3. 侵犯個人隱私權和期望
人們希望以簡單的方式做事,這已不是什麼秘密。這意味著他們可能會做不應該做的事情,以使工作更輕鬆並節省時間。不幸的是,這可能會導致敏感資訊在(理想情況下)安全的公司內部系統之外共享。
受保護的資訊可能會無意中被共享
南加州大學索爾·普萊斯公共政策學院討論了生成式人工智慧對受保護的健康資訊的風險。在某些情況下,醫療保健提供者將患者受 HIPAA 保護的資訊輸入聊天機器人,以幫助生成報告和簡化流程。當他們這樣做時,他們會將受保護的資料輸入第三方系統,這些系統可能不安全,並且沒有要處理的患者內容:
“受保護的健康資訊不再屬於衛生系統內部。一旦您在 ChatGPT 中輸入某些內容,它就會儲存在 OpenAI 伺服器上,並且不符合 HIPAA。這才是真正的問題,從技術上講,這就是資料洩露。”
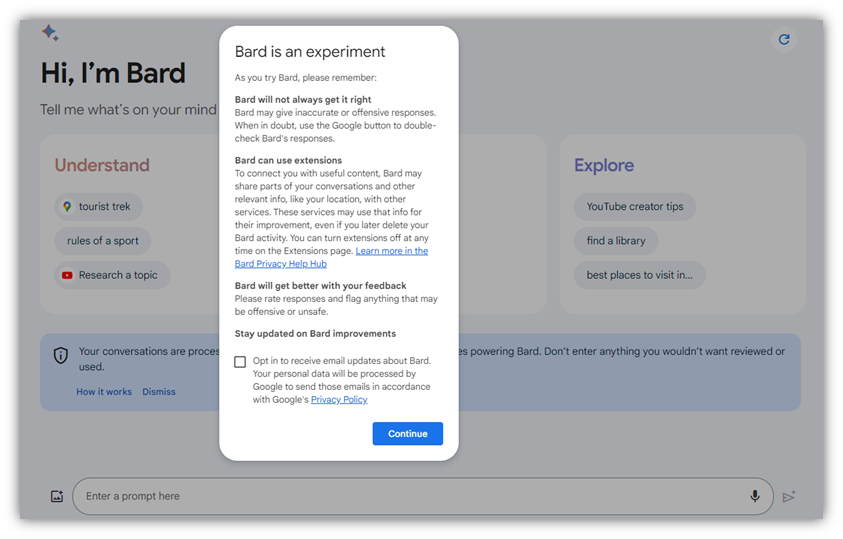
此外,不僅僅是人工智慧可以訪問您共享的內容。Google Bard 是 Google 對 ChatGPT 的回應,它預先警告使用者,與該工具的對話將被人類稽核者看到:

儘管我確信 Google 擁有非常可愛的員工,但他們無權檢視患者的受保護健康資訊 (PHI)。
生成式人工智慧工具可能會導致個人資料無意洩露
關於生成式人工智慧和其他人工智慧技術廣泛採用的重大擔憂之一是隱私帶來的潛在風險。由於生成式人工智慧使用來自許多資源的大量資料,因此其中一些資料可能會洩露您的個人詳細資訊、生物識別資訊,甚至與您的位置相關的資料。
在國際隱私專業人士協會 (IAPP) 的一篇文章中,Littler Mendelson 隱私和資料安全實踐小組聯合主席 Zoe Argento 指出了一些生成式 AI 風險和有關資料披露的擔憂:
“生成式人工智慧服務可能會無意中或故意洩露使用者的個人資料。例如,作為標準操作過程,該服務可以使用來自使用者的所有資訊來微調基本模型分析資料和生成響應的方式。因此,個人資料可能會被納入生成人工智慧工具中。該服務甚至可能向其他使用者披露查詢,以便他們可以看到提交給該服務的問題的示例。”
每當你在公司的一份長達一英里的使用者協議上點選“接受”時,你就放棄了你的隱私權,甚至沒有意識到你正在放棄什麼。(當然,即使你讀了它,除非你是一名律師,但這並不意味著你會完全理解對你的要求,因為所有的“法律術語”都會向你丟擲。)當公司說“附屬公司”時”和“合作伙伴”可能會使用您的個人資料和任何其他提供的資訊,但您不知道這對於您的資料的去向或使用方式意味著什麼。
企業在與此類服務提供商合作時應注意的與隱私相關的生成式人工智慧風險和擔憂有哪些示例?Argento 確定了三個主要問題:
“第一個問題涉及向人工智慧工具披露個人資料。這些披露可能會導致僱主失去對資料的控制,甚至導致資料洩露。其次,生成式人工智慧服務提供的資料可能是基於違反資料保護要求(例如通知和適當的法律依據)處理和收集個人資料。僱主可能會對這些違規行為承擔一些責任。第三,在使用生成式人工智慧服務時,僱主必須根據適用的法律確定如何遵守行使資料權利的請求。”
但是,在使用生成式人工智慧服務時,如何提高資料的隱私性和安全性呢?
- 評估每個生成人工智慧服務提供商,根據他們的政策、實踐和其他因素確定他們的潛在風險水平。
- 指定如何處理、儲存和銷燬您的資料。
- 確保服務提供商的流程滿足監管資料安全和隱私要求。
- 與提供商協商,讓他們在合同上同意強大的安全和資料隱私流程(並確保以書面形式達成)。
4. 使用 Deepfakes 來羞辱和攻擊個人
生成式人工智慧工具甚至被用來建立深度偽造的色情材料(影片、影象等),對受害者造成精神、情感、聲譽和經濟傷害。許多名人(通常是女性)的個人肖像被用來製作他們進行性行為的欺詐性影象和影片。似乎這還不夠令人不安,這項技術還被用來製作兒童色情作品。
當然,這項技術不僅僅用於製作名人的虛假內容。它還為普通人成為深假媒體的受害者打開了大門。
想象一下,一個女人與她的未婚夫分手了。她的前未婚夫對這種情況感到憤怒,並決定向她發洩,因為他想讓她痛苦。他使用生成式人工智慧製作“報復性色情內容”(即受害者不知道或不同意的對方色情內容),並在受害者不知情的情況下將影片傳送給她的老闆、朋友和家人。想象一下她將因這次有針對性的攻擊而面臨的問題和羞辱。
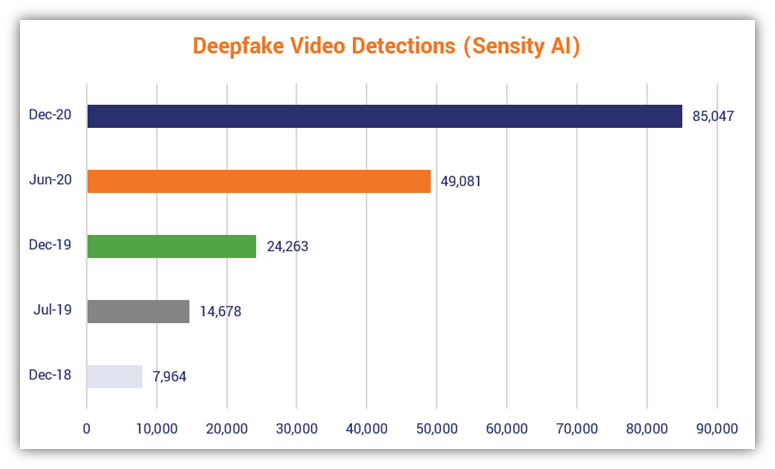
但這到底是一個多大的問題呢?Deeptrace AI(現為 Sensity AI) 2019 年的一項研究發現,他們在網上發現的 14,678 個深度造假影片中,高達 96% 被歸類為未經同意的色情內容。截至 2020 年 12 月,Sensity AI 發現的 Deepfake 數量躍升至 85,000 多個。如下圖所示,線上深度偽造影片的數量基本上每六個月就會翻一番:
5. 開發新的網路攻擊渠道和方法
壞人喜歡生成式人工智慧工具,因為它們可以用來實施新的攻擊並使他們的工作變得更容易。以下是網路犯罪分子利用這些技術做壞事的一些簡單示例:
網路犯罪分子可以製作更可信的網路釣魚訊息
每個人都知道常見網路釣魚電子信箱的明顯跡象:不尋常的語法、錯誤的拼寫、錯誤的標點符號等。這些郵件針對的是容易實現的目標(即,對網路意識實踐一無所知的毫無戒心的使用者)。
透過消除不良語法並修復您在大多數網路釣魚電子信箱中常見的拼寫錯誤和標點符號,壞人可以使他們的訊息更加真實。他們可以利用這些欺詐性訊息來誘騙更多受害者放棄敏感資料或做一些他們以後會後悔的事情。例如,他們可以建立來自您的銀行、服務提供商、國稅局甚至您的僱主的看似真實的電子信箱。
以下是 ChatGPT 在不到 3 秒內拼湊出的一封信的快速示例:

攻擊者為使網路釣魚電子信箱更可信而填寫的大部分資訊都可以在 Google 上找到(公司的地址和資訊、目標的名稱和地址、銀行代表的姓名和職務等),然後他們可以將網路釣魚連結嵌入到內容中誘騙使用者在欺詐性登入頁面上輸入憑據。
生成式人工智慧內容還可以透過使用獨特的措辭來代替電子信箱垃圾郵件過濾器程式設計搜尋的相同重複訊息,從而幫助網路犯罪分子繞過傳統的檢測工具。
社會工程師和其他壞人可以更有效地進行“骯髒行為”
您知道透過自動錄音收到的那些煩人的垃圾郵件電話嗎?壞人可以利用這些電話作為記錄您聲音樣本的機會。然後,這些樣本可以用來生成虛假對話——例如,他們可以用你的聲音說出銀行或金融機構要求的特定短語,或者給下屬打一個簡短的電話。
根據 Pindrop 的研究:
“[...] 一旦某個賬戶成為網路釣魚或賬戶接管攻擊中欺詐者的目標,60 天內針對該賬戶的二次欺詐電話的可能性就在 33% 到 50% 之間。即使在初次攻擊 60 天后,先前目標帳戶的欺詐風險仍然極高,在 6% 到 9% 之間。
我們還發現,在大多數情況下,欺詐者在與代理交談時非常成功地通過了驗證過程。在分析我們的客戶資料時,我們發現欺詐者在 40% 到 60% 的情況下能夠透過代理驗證。”
在過去的幾年裡,我們已經看到了此類詐騙的例子。2019 年,全球新聞機構報道稱,一名詐騙者透過這種方式從一家公司執行長那裡騙取了 220,000 歐元(243,000 美元) 。他們使用老闆聲音的深度偽造錄音,冒充公司母公司執行長的上級。
現在,還有一些壞訊息:PLOS One 上發表的一項針對 529 人的研究顯示,四分之一的受訪者無法識別深度偽造音訊。即使向他們提供了語音深度偽造的示例,結果也僅略有改善。如果這個調查群體準確地代表了美國人口,那就意味著 25% 的人容易陷入深度造假。大約有 83,916,251 人!
壞人可以使用生成人工智慧來嘗試識別變通辦法並獲取秘密
看一下 Mashable 分享的示例,其中顯示網路安全研究人員能夠發現 ChatGPT 和 Google Bard 在出現提示時會吐出 Windows 10 Pro 和 Windows 11 Pro 金鑰。他們透過將他們的要求融入到一個更大的故事中來欺騙他們。
值得慶幸的是,在這種情況下,Digital Trends 報告稱,他設法獲得的金鑰是通用許可證金鑰,這意味著它們僅提供有限的功能,並且某些功能受到限制。
當然,許可證金鑰並不像其他型別的金鑰(例如加密金鑰)那麼令人擔憂。但想象一下,如果這些生成式人工智慧工具之一設法收集您在 GitHub 帖子中意外洩露或在勒索軟體攻擊中被盜的加密金鑰。
6. 生成式人工智慧引發新的智慧財產權和版權侵權問題
正如我們之前提到的,生成式人工智慧技術與傳統人工智慧的不同之處在於,它們在現有材料的巨大資料集上根據模式從中汲取“靈感”。這就是為什麼人工智慧生成的詩歌聽起來非常人性化,在某些情況下甚至很美麗(儘管情況並非總是如此)。
但誰擁有人工智慧生成的作品呢?如果生成式人工智慧輸入不同藝術家的作品作為靈感(即找到可以與其演算法一起使用的模式),那麼誰擁有所產生的創意內容或擁有權利?
這是行業內仍在“討論”的問題,就連美國版權局也在努力尋找明確的答案。作為今年早些時候啟動的人工智慧計劃的一部分,該辦公室延長了對其人工智慧查詢通知的公眾評論請求。根據其在《聯邦公報》上釋出的調查通知:
“為了為該辦公室的研究提供資訊並幫助評估該領域的立法或監管措施是否必要,該辦公室尋求對這些問題的評論,包括涉及使用受版權保護的作品來訓練人工智慧模型的問題、適當的透明度和披露水平尊重受版權保護的作品的使用以及人工智慧生成的輸出的法律地位。”
為了好玩,我向 Google Bard 詢問了其對生成式 AI 風險以及與智慧財產權和版權問題相關的擔憂的看法:
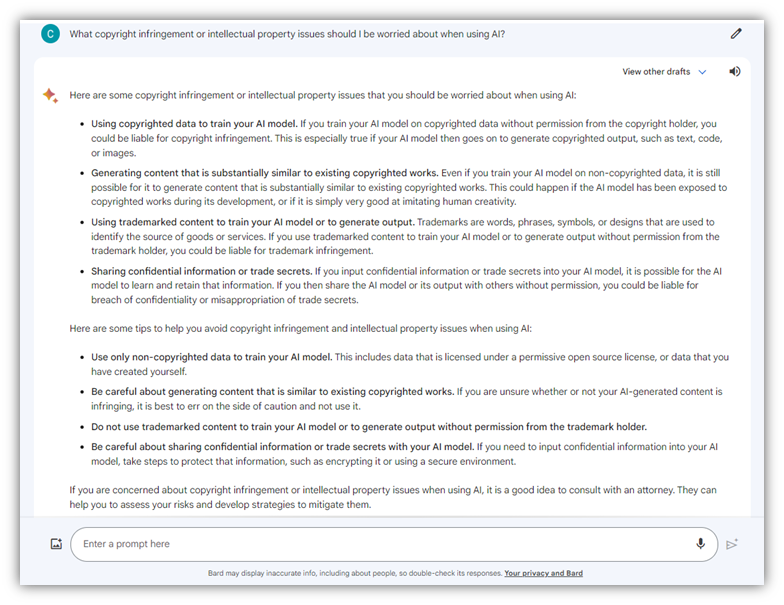
生成式人工智慧與傳統人工智慧之間的差異概述
生成式人工智慧是人工智慧的一個子類別,旨在建立(生成)新內容 - 影象和插圖、程式碼、影片等。它依靠機器學習 (ML)(人工智慧的一種)來分析和檢測模式在提供的(現有)資料中,然後建立遵循類似模式的新內容。
從某種意義上說,生成式人工智慧讓我想起了博格人—— 《星際迷航》宇宙中的一種部分合成的生物物種,它們共享一個集體意識,一個“蜂巢思維”。對於任何遇到他們道路的人來說,博格集體都是一個可怕的敵人。他們的技術進步很大程度上歸功於被同化的個體在一生中獲得的大量集體知識,包括思想、經驗、技能、技術和個人創造力。一旦被同化,他們所有的知識,甚至他們的個性,都將交給集體。(“抵抗是徒勞的。”)
同樣,生成式人工智慧工具對於企業、消費者和內容創作者來說可以成為令人難以置信的資源,因為它們透過借鑑其他人建立的基礎結構和概念來創造新的有趣的東西。因此,生成式人工智慧工具可以幫助組織節省時間、金錢和資源。
有關公司如何在營銷中使用生成式人工智慧的一個絕妙示例,請檢視吉百利如何為消費者製作大量本地個性化廣告,而無需與知名印度演員重新拍攝數百或數千個個人影片:
但正如我們所知,還必須考慮許多生成式人工智慧風險和問題。現在我們已經瞭解了其中一些風險是什麼,讓我們談談可以採取哪些措施來解決這些風險。
正在採取哪些措施來解決基於生成人工智慧的風險和擔憂
如果您不知道什麼是真實的、什麼是假的,那麼幾乎不可能做出明智的決定。企業和政府都在採取措施打擊惡意生成人工智慧攻擊,並將辨別力重新交到消費者手中。
但這些努力還處於起步階段——我們剛剛開始瞭解需要採取哪些步驟、哪些步驟會有幫助,以及哪些看似好的步驟可能會適得其反。我們需要一段時間才能弄清楚我們需要採取哪些措施來保證生成式人工智慧的安全。以下是一些正在進行的努力……
歐盟成員國正在討論人工智慧法案
2021年,歐洲議會提出了《人工智慧法案》,要求在使用生成式人工智慧時進行披露。它還禁止在多種應用程式中使用人工智慧,包括:
- “實時”和“後期”生物特徵識別和分類系統(需要司法授權的執法除外);
- 社會評分(即根據個人特徵或社會行為對人進行分類);
- 透過抓取閉路電視錄影和網際網路資源建立的面部識別系統侵犯了個人的隱私權和其他人權;
- 情緒識別系統可能會導致對一個人做出錯誤的結論或決定;和
- 基於某些型別資料的預測警務系統。
截至 2023 年 6 月,歐洲議會議員 (MEP) 開始對該法案進行談判。
美國領導人呼籲制定有關安全和安全使用人工智慧的標準和指南
10月30日,白宮釋出了拜登總統關於安全、可靠、可信地開發和使用人工智慧的行政命令,旨在為安全可靠地使用人工智慧技術(包括生成式人工智慧系統)。
該行政命令概述了幾個關鍵優先事項和指導原則。以下是每個類別的快速概述;請記住,每個內容所涉及的內容遠比我在快速概述中所能涵蓋的內容要多得多:
- 透過標準和最佳實踐確保安全、保障和信任。目標是“建立指導方針和最佳實踐,以促進達成共識的行業標準,以開發和部署安全、可靠和值得信賴的人工智慧系統。” 這涉及建立標準,開發用於生成人工智慧的 NIST 人工智慧風險管理框架(AI RMF 1.0,也稱為 NIST AI 100-01)的“配套資源” (因為現有框架無法解決這些風險),以及設定基準。
- 促進創新、競爭和合作。其目的是透過簡化移民流程、時間表和標準,建立新的人工智慧研究機構,以及制定涉及人工智慧和生成人工智慧內容的發明專利指南,更容易地吸引和留住更多人工智慧人才。
- 促進公平和公民權利。對某些人工智慧技術的擔憂是,它可能會導致“非法歧視和其他傷害。”該行政命令旨在為執法部門、政府福利機構和計劃以及與住房和相關係統有關的人工智慧使用提供最佳實踐和保障措施建議。租賃。
- 保護美國消費者、學生、患者和工人。這包括將人工智慧相關的安全、隱私和安全標準與各個部門的實踐結合起來,包括“醫療保健、公共衛生和人類服務”、教育、電信和交通。
- 保護美國人的隱私。這都是為了減輕與個人資料收集和使用相關的基於人工智慧的隱私風險。這需要建立新的和更新的指南、標準、政策程式,並“在可行和適當的情況下”納入隱私增強技術(PET)。
- 推進美國聯邦政府對人工智慧的使用。這裡的目標是為聯邦機構安全可靠地管理和使用人工智慧建立指導和標準。這包括擴大培訓、推薦指南、保障措施和最佳實踐,以及消除負責任地使用人工智慧的障礙。
- 加強美國的全球領導力。我們的想法是透過領導建立人工智慧相關框架、標準、實踐和政策的協作努力,走在人工智慧相關舉措的最前沿。
毫無價值的是,行政命令中指出的一件事是開發安全機制,幫助消費者和使用者區分真實的內容和媒體與“合成”的內容和媒體。據行政長官稱:“[……] 我的政府將幫助開發有效的標籤和內容來源機制,以便美國人能夠確定內容何時是使用人工智慧生成的,何時不是。”
這引出了我們的下一點……
全球組織正在共同制定人工智慧媒體標準
八月份,我們向您介紹了 C2PA——也稱為內容來源和真實性聯盟。這一開放技術標準旨在幫助人們使用公鑰密碼學和公鑰基礎設施 (PKI) 來識別和區分真實影象、音訊和影片內容與虛假媒體。
這是一個由數十位行業領導者組成的聯盟,他們共同致力於建立可在多個平臺上使用的通用工具,以證明資料來源(即證明媒體檔案和內容的真實性和準確性的歷史資料) 。
相機制造商徠卡最近釋出了新款 M11-P 相機,該相機內建了內容憑證,可以從拍攝照片的那一刻起進行內容驗證。
美國立法者旨在為未來針對違法者採取法律行動鋪平道路
雖然 PornHub、Twitter 和其他平臺確實禁止了人工智慧生成的色情內容,但這還不足以減少新的(有害的)內容的建立和傳播。現在,州和聯邦立法者正在嘗試這樣做。
HR 3106(也稱為“防止親密影象深度偽造法案”)是一項提交給美國眾議院司法委員會的聯邦法案,旨在禁止披露未經同意的親密數字描述。這些是使用數字處理建立或更改的人的影象或影片,其中包含露骨的性內容或其他親密內容)。
那些犯下該法案所列罪行的人可能會面臨民事訴訟,並導致向受害者支付所造成的損失。根據罪行的嚴重程度,他們還可能面臨監禁、罰款和其他處罰。
紐約州最近通過了類似的立法。紐約州州長 Hochul 簽署了參議院法案 S1042A,該法案禁止“非法傳播或出版透過數字化建立的私密影象以及對個人的露骨色情描述”。該法律修改了該州刑法的一些細則並廢除了另一條。
關於生成式人工智慧風險和危險的最終想法
生成式人工智慧正在迅速發展,並在其能力方面擁有很大的前景。除了降低成本和加快某些創意流程之外,這些工具還提供了獨特的內容建立方式,因為它們建立在現有媒體和內容中識別的模式之上。
生成式人工智慧的風險大於收益嗎?這還有待爭論。但無可爭議的是,生成式人工智慧已經存在,並且現在已經成為我們世界的一部分。隨著越來越多的企業和使用者採用這些技術,他們有越來越大的責任來確保負責任地使用這些生成工具。他們必須以促進安全、保障和信任的方式使用它們,並且不會造成傷害(有意或無意)。
最近新聞
2025年03月03日
2025年03月03日
2025年03月03日
2025年02月19日
2025年02月19日
2025年02月19日
2025年02月18日
2025年02月17日
需要幫助嗎?聯絡我們的支援團隊 線上客服