行業新聞與博客
Google 的 Naptime 框架將利用人工智能促進漏洞研究
Google Project Zero 的漏洞研究人員推出了新框架 Naptime,該框架將用於支持大型語言模型 (LLM) 開展漏洞研究。
Naptime 計劃於 2023 年中期啓動,旨在改進漏洞發現方法,特別注重自動化變體分析。
該項目之所以被稱為“午睡時間計劃”,是因為它有可能讓我們在有規律的午睡的同時,還能幫助我們完成工作,”零計劃的謝爾蓋·格拉祖諾夫和馬克·布蘭德在 6 月 20 日的一篇博客文章中寫道。
Google Naptime 的工作原理
Naptime 框架的目標是使 LLM 能夠執行與人類安全專家的迭代、假設驅動方法密切相關的漏洞研究。
Glazunov 和 Brand 表示:“這種架構不僅增強了代理識別和分析漏洞的能力,而且還確保了結果的準確性和可重複性。”
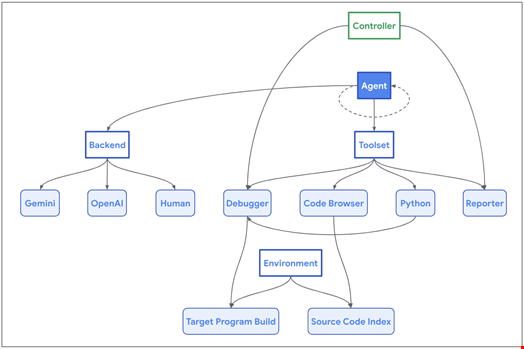
該框架的架構以人工智能代理與其一組專用工具之間的交互為中心,旨在模仿人類安全研究人員和目標代碼庫的工作流程。
這些工具包括:
- 代碼瀏覽器使代理能夠瀏覽目標代碼庫,就像工程師使用 Chromium 代碼搜索一樣
- Python使代理能夠在沙盒環境中運行 Python 腳本進行中間計算,併為目標程序生成精確而複雜的輸入
- 調試器允許代理與程序交互並觀察其在不同輸入下的行為。為了確保一致的重現和更容易檢測內存損壞問題,該程序使用 AddressSanitizer 進行編譯,調試器捕獲指示與安全相關的崩潰的各種信號
- 報告器為代理提供了一種結構化的機制來傳達其進展
- 當 AI 代理觸發時,控制器會驗證是否滿足成功條件(通常是程序崩潰)。它還允許代理在無法進一步進展時中止任務,從而防止停滯
谷歌的 Project Zero 表示,該框架與模型和後端無關。研究人員寫道,它甚至可以被人類代理用來生成成功的軌跡,以進行模型微調。
Meta 的 CyberSecEval2 基準測試中取得最高分
Naptime 框架建立在 Google Project Zero 制定的一套指導原則之上,旨在提高多用途 LLM 在漏洞發現方面的性能。
這些原則是在 Meta 安全研究人員推出 CyberSecEval2(用於發現和利用內存安全問題的最新 LLM 基準)之後制定的。
Glazunov 和 Brand 寫道:“我們在由 LLM 提供支持的漏洞研究框架中實現了這些原則,這使得 CyberSecEval2 基準測試性能比原始論文提高了 20 倍。”
例如,Project Zero 的研究人員進行了兩組 CyberSecEval2 測試,分別是“高級內存損壞”和“緩衝區溢出”,其中 GPT 4 Turbo 是 AI 代理,其餘則使用 Naptime 工具。他們在“緩衝區溢出”測試中取得了 1.00 的新高分(Meta 論文中為 0.05),在“高級內存損壞”測試中取得了 0.76 的新高分(Meta 論文中為 0.24)。
“如果配備正確的工具,當前的 LLM 確實可以開始執行(誠然是相當基礎的)漏洞研究!然而,解決孤立的奪旗式挑戰而不產生歧義(總是存在錯誤,您總是通過提供命令行輸入來找到它,等等)與執行自主的攻擊性安全研究之間存在很大差異,”Project Zero 研究人員表示。
他們認為,安全界還需要制定更困難、更現實的基準,以有效監控此類舉措的進展。
最近新聞
2025年03月03日
2025年03月03日
2025年03月03日
2025年02月19日
2025年02月19日
2025年02月19日
2025年02月18日
2025年02月17日
需要幫助嗎?聯繫我們的支持團隊 在線客服